機能
タスクパネルウィンドウから、次の機能を利用できます。
- ページ (Page)
- コンテンツ (Content)
- フォーム (Forms)
- テキスト認識 (Recognize Text)
- 保護 (Protection)
- 電子署名 (Sign & Certify)
- 文書処理 (Document Processing)
- JavaScript (JavaScript)
- アクセシビリティ (Accessibility)
- 分析 (Analyze)
テキスト認識 (Recognize Text) : OCR
テキスト認識では、スキャナなどから読み込まれた画像データに対してテキストを付加できます。これはパネルウィンドウの【ツール → テキスト認識】から行えます。同時に画像も補正するならば、[スキャンされた PDF を最適化]から実行します。
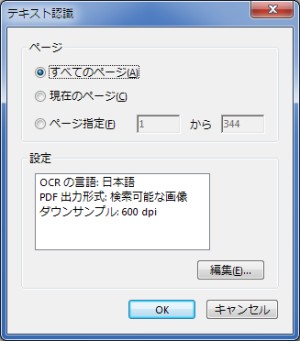
[編集]をクリックすることで、テキスト認識の設定を変更できます。
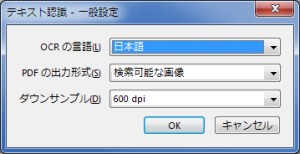
| 出力形式 | OCR以外の特徴 | ||
|---|---|---|---|
| 検索可能な画像 |
|
||
| 検索可能な画像 (非圧縮) |
|
||
| ClearScan |
|
テキスト認識を実行すると予期せずページが回転されることがありますが、この自動回転を無効にする方法はないようです。 Disabling the auto rotation while doing OCR | Adobe Community how do i turn off auto rotate during ocr (Scan and Optimize)
サイズの制限
テキスト認識できるのは、用紙サイズが45×45インチまでのページです。これを超えるページを認識しようとすると「次の理由により、このページのテキスト認識 (OCR) を実行できませんでした。このページは、最大用紙サイズ (45 × 45 インチ) を超えています。」としてエラーとなります。
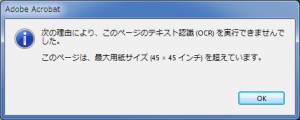
この問題は、ページの画像サイズを縮小することで解決できます。45インチという制約は、画像の解像度が72ppi (ピクセル/インチ) とすると
45in × 72ppi = 3240px
であり、画像の幅と高さを3240ピクセルに収める必要があります。この画像サイズの変更には、IrfanViewの[ファイル形式の一括変換]が便利です。このツールでは、複数のファイルをインチ指定で変換できます。
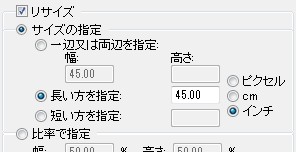
IrfanViewのファイル形式の一括変換
認識されたテキストの確認
テキスト認識の結果は画像に透明なテキストで重ねられるため、それを直接視認することはできません。しかし次に紹介する方法を用いれば、この透明テキストを確認することができます。
テキストを他のエディタに貼り付ける
Acrobat上では透明ですが、テキストをクリップボードにコピーしてエディタに貼り付ければ、そこでは通常のテキストとして確認できます。
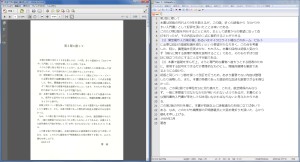
透明テキストの色を変更する
透明だから見えないのであって、フォントに色を設定することで見えるようになります。それには、まずパネルウィンドウの【ツール → コンテンツ】で[文書テキストを編集]を選択します。そして対象とするテキストを選択した状態で右クリックし[プロパティ]を開きます。
回転されているテキストは、この方法でプロパティを表示できません。
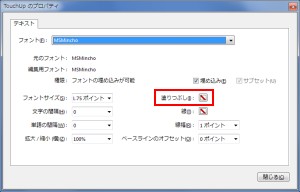
そして[塗りつぶし]で、画像の文字とは異なる色を選択します。そうすることで透明テキストに色が付き、テキストを確認できるようになります。
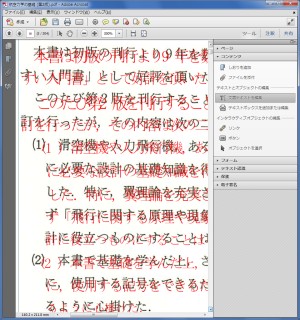
保護 (Protection)
パスワード (Password)
パネルウィンドウの【ツール → 保護 → 暗号化】から設定できます。
次の暗号化レベルから選択できます。
- 40-bit RC4 (Acrobat 3.0 およびそれ以降)
- 128-bit RC4 (Acrobat 5.0 およびそれ以降)
- 128-bit RC4 (Acrobat 6.0 およびそれ以降)
- 128-bit AES (Acrobat 7.0 およびそれ以降)
- 256-bit AES (Acrobat X およびそれ以降)
パネルウィンドウの【ツール → 保護 → 非表示情報を検索して削除】から実行できます。
- 非表示のテキスト
- メタデータ
- 注釈
- 添付ファイル
などを削除できます。
文書処理 (Document Processing)
画像の補正
ツールの[文書処理]の[スキャンされた PDF を最適化 (Optimize Scanned PDF)]で、PDFに埋め込まれた画像を補正できます。
アクセシビリティ (Accessibility)
読み上げ (Read Out Loud)
メニューの【表示 → 読み上げ → 読み上げを起動】から、読み上げを開始できます。