文字コード
用語
- 文字セット (character set) / 文字集合
- 同種の文字の集合。英語の文字をまとめたASCII文字集合や、それにカタカナを追加したJIS X 0201、世界中の文字をまとめたUnicodeなど
- 文字コード (character code)
- 文字セットの個々の文字に番号を割り当てたコード体系。UnicodeやShift_JISなど
- 文字コードセット (character codeset) / コードセット
- 文字コードが割り当てられた文字の集合。文字コードと同義
- 文字エンコーディング (character encoding) / 文字符号化方式
- 文字コードの符号化 (エンコード) 方式。UnicodeのUTF-8やUTF-16など
- コードページ (code page)
- 文字セットを符号化 (エンコード) するための変換テーブル。MicrosoftのWindows code pageやIBMのEBCDIC code pageなど
コード体系によるコードの違い
| 文字コード | 「あ」のコード |
|---|---|
| UTF-8 | 0xE38182 |
| UTF-16 | 0x3042 |
| Shift_JIS | 0x82A0 |
| EUC-JP | 0xA4A2 |
UCS (Universal multi-octet coded Character Set)
UCSとは、符号化された文字集合の国際標準です。UCSとは|ISO/IEC 10646|Universal multi-octet coded Character Set - IT用語辞典 e-Words
UTF (UCS Transformation Format)
UTFとは、UCS-2やUCS-4で記述された文字列を、バイト列に変換する方式です。これには次の4種類があります。
- UTF-7 … 7ビットで表現 (メールで使用)
- UTF-8 … 1文字を1~6バイトの可変長のバイト列に変換
- UTF-16 … UCS-2の中に、UCS-4の一部の文字を埋め込む
- UTF-32 … すべてのUCS-4文字を、4バイトで表現
UCS-2
UCS-2では個々の文字に2バイトの番号 (コードポイント) を割り当て、0~65,535番までに対応する文字が定められています。これの文字符号化方式には、UTF-8、UTF-16やUTF-32などが利用できます。UCS-2とは|BMP|基本多言語面|Universal multi-octet Character Set 2 - IT用語辞典 e-Words
UCS-4
UCS-4は4バイトで定義され、上位のバイトからそれぞれ
- 群 (group)
- 面 (plane)
- 区 (row)
- 点 (cell)
と呼ばれます。このうち群00の面00は、UCS-2として定義されています。UCS-4とは|Universal multi-octet Character Set 4 - IT用語辞典 e-Words
Unicode
Unicodeでは、すべての文字はU+0000~U+10FFFFの範囲に割り当てられています。そしてこのUnicode値 (Unicode value) はコードポイント (Code point) と呼称され、
- UTF-8 … コードポイントがU+7Fまでなら変換せず8bitで、それ以降は値に応じて16~48bit
- UTF-16 … コードポイントがU+FFFFまでなら変換せず16bitで、それ以降は32bit
- UTF-32 … コードポイントを変換せず、つねに32bit
の3つのエンコーディング方式 (符号化方式) により符号化されます。
Find all Unicode characters from Hieroglyphs to Dingbats – CodepointsUTF-8
下表の規則に従い符号化します。1と0が指定されている場所はその値に固定で、xの場所にコードポイントのビットを右から詰めていきます。
| コードポイントの範囲 (16進数) | 符号化後のビット列 |
|---|---|
| 00000000~0000007F | 0xxxxxxx |
| 00000080~000007FF | 110xxxxx 10xxxxxx |
| 00000800~0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000~0010FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00110000~ |
参考
- Tech Basics/Keyword:UTF-8 - @IT 打越浩幸 (2016/03/28)
UTF-16
コードポイントがU+FFFFまでの範囲ならばそのまま2バイトで、それ以降のU+10FFFFまでならばサロゲートペアを用いて4バイトで表現します。
サロゲートペア (Surrogate Pair) / 代用対
2バイトの空間に収まらないU+010000~U+10FFFFの文字を、4バイトで表現する方法です。
- 上位サロゲート (High Surrogates) / 上位2バイト … U+D800 ~ U+DBFF (1024通り)
- 下位サロゲート (Low Surrogates) / 下位2バイト … U+DC00 ~ U+DFFF (1024通り)
コードポイントとの相互変換
- H … 上位サロゲート
- L … 下位サロゲート
- C … コードポイント
とするとき、コードポイントからサロゲートペアへは、次の式で変換できます。
H = (C - 0x10000) / 0x400 + 0xD800; L = (C - 0x10000) % 0x400 + 0xDC00;
逆にコードポイントへは、次の式となります。
C = (H - 0xD800) * 0x400 + (L - 0xDC00) + 0x10000;3.7 Surrogates - Unicode 3.0.0 サロゲートペア - Unicode - Wikipedia
参考
- 特殊文字 : サロゲート ペア | MSDN
- サロゲートペア入門:CodeZine(コードジン) さなみ (2007/08/28)
参考
- UTF-8とUTF16の違いは? (2001/09/14)
UTF-32
コードポイントをそのまま用いて、つねに32bit (4byte) で表現します。
BOM (Byte Order Mark)
BOMとは、エンディアンを示すためにファイルの先頭に記述される値です。UTF-8ではエンディアンは無関係ですが、Unicodeであることを示すために付けられることがあります。BOMとは|Byte Order Mark - IT用語辞典 e-Words
| BOMの値 | エンコーディング形式 | 符号化方式 | |
|---|---|---|---|
| EF BB BF | UTF-8 | UTF-8 | |
| FE FF | UTF-16, big-endian | (UTF-16BE) | UTF-16 |
| FF FE | UTF-16, little-endian | (UTF-16LE) | |
| 00 00 FE FF | UTF-32, big-endian | (UTF-32BE) | UTF-32 |
| FF FE 00 00 | UTF-32, little-endian | (UTF-32LE) | |
単にUTF-16やUTF-32と呼称される場合には、バイト順はそのBOMによって決定されます。Q: What are some of the differences between the UTFs? - FAQ - UTF-8, UTF-16, UTF-32 & BOM
参考
CJK統合漢字 (CJK unified ideographs)
CJK統合漢字 (CJK unified ideographs)
中国語、日本語、韓国語で使用される漢字を統合したもの。CJKはChina、Japan、Koreaの頭文字をとったもの。
CJK統合漢字では、中国語と日本語、韓国語に使われる漢字のうち、字形と文字の意味がよく似ているものを同じ漢字として扱う。このため、日本語の文中に中国語を混ぜたい場合などに不都合があることが指摘されている。
Unicodeでは全部で65,536種類の文字を割り当てられるが、CJK統合漢字はこのうちの20,902文字を使用している
CJK統合漢字 - 意味・説明・解説 : ASCII.jpデジタル用語辞典
絵文字 (emoji)
ブラウザによって表示される画像が異なり、サポートされない絵文字もあります。
| 名称 | Unicodeの範囲 | 表示例 |
|---|---|---|
| UMBRELLA WITH RAIN DROPS..HOT BEVERAGE Miscellaneous Symbols | 2614~2615 | ☔ ☕ |
| Regional indicator symbols※1 Enclosed Alphanumeric Supplement | 1F1E6~1F1FF | 🇦 🇧 🇨 🇩 🇪 🇫 🇬 🇭 🇮 🇯 🇰 🇱 🇲 🇳 🇴 🇵 🇶 🇷 🇸 🇹 🇺 🇻 🇼 🇽 🇾 🇿 |
| SQUARED CJK UNIFIED IDEOGRAPH Enclosed Ideographic Supplement | 1F232~1F23A | 🈲 🈳 🈴 🈵 🈶 🈷 🈸 🈹 🈺 |
| GRINNING FACE WITH SMILING EYES..NEUTRAL FACE Emoticons | 1F601~1F610 | 😁 😂 😃 😄 😅 😆 😇 😈 😉 😊 😋 😌 😍 😎 😏 😐 |
サポートされる絵文字のすべては、Full Emoji Dataで確認できます。
ページサイズが大きいため、表示に時間がかかることがあります
種類による区分
種類ごとに分頼された絵文字を、Emoji Annotationsで確認できます。このページでは個々の絵文字の文字コードを、その要素のtitle属性またはリンク先のページで確認できます。
また、📙 Emojipediaでも種類ごとに確認できます。
参考
- 日本発のケータイ絵文字が世界標準に Unicode 6.0で - ITmedia ニュース (2010/10/14)
- Unicode絵文字にプログラマや歌手など11職種が追加、性別も指定可能に。既存33字も性別選択に対応 - Engadget Japanese ITTOUSAI (2016/07/15)
Unicodeブロック
ブロックとは、Unicodeのコード表を系統だてるための文字の分類です。Block - Glossary
| Unicodeブロック | UTF-8 | UTF-16 | 文字 |
|---|---|---|---|
| Hiragana |
E38180 | 3040 | |
| E38181 | 3041 | ぁ | |
| E38182 | 3042 | あ | |
| E38183 | 3043 | ぃ | |
| ︙ | |||
| Katakana |
E382A0 | 30A0 | ゠ |
| E382A1 | 30A1 | ァ | |
| E382A2 | 30A2 | ア | |
| E382A3 | 30A3 | ィ | |
| ︙ | |||
| CJK Unified Ideographs |
E4B880 | 4E00 | 一 |
| E4B881 | 4E01 | 丁 | |
| E4B882 | 4E02 | 丂 | |
| ︙ | |||
| Halfwidth and Fullwidth Forms
Halfwidth and Fullwidth Forms |
EFBC80 | FF00 | |
| EFBC81 | FF01 | ! | |
| EFBC82 | FF02 | " | |
| ︙ |
異体字セレクタ (Ideographic Variation Sequence : IVS)
異体字セレクタにより指定された文字を正しく表示するには、それに対応したソフトウェアとフォントが必要です。
| コード | 表示例 | 文字参照による表記 | |||
|---|---|---|---|---|---|
| 表記1 | 表示例1 | 表記2 | 表示例2 | ||
| U+845BU+E0100 | 葛󠄀 | 葛󠄀 |
葛󠄀 | 葛󠄀 |
葛󠄀 |
| U+845BU+E0101 | 葛󠄁 | 葛󠄁 |
葛󠄁 | 葛󠄁 |
葛󠄁 |
参考
正規化 (Normalization)
「ガ」と「ガ」のように、外見は似ているが異なる文字を統一する方法を考えます。
参考
- Unicode Consortium
- Code Charts - Unicode Consortium (PDFによる一覧表)
- Character Name Index (名前の一覧)
- Unicode Terminology: Japanese - English (専門用語の英語訳)
- Code Charts - Unicode Consortium (PDFによる一覧表)
- Find all Unicode characters from Hieroglyphs to Dingbats – Codepoints
- Unicodeエンコード方式 Ken Lunde (2001/09/01)
- Tech Basics/Keyword:Unicode(ユニコード) - @IT 打越浩幸 (2016/03/10)
- Unicodeとは 〔 ユニコード 〕 - IT用語辞典 e-Words
バージョン
記事一覧
ISO-2022-JP (JIS)
日本語の電子メールで利用されています。
Content-Type: text/plain; charset="iso-2022-jp" Content-Transfer-Encoding: 7bit
- JISコードとは - IT用語辞典
- Tech TIPS:メールの文字コードを理解する - @IT 打越浩幸 (2006/02/18)
Shift_JIS (シフトJIS)
次のコードを基に実装されています。
- JIS X 0201 (JIS C 6220) … 半角英数字と半角カナ
- JIS X 0208 (JIS C 6226) … 第1水準と第2水準の漢字、それに非漢字
漢字は次の範囲が定義されています。
- 第1水準 … 0x889F (亜) ~ 0x9872 (腕)
- 第2水準 … 0x989F (弌) ~ 0xEAA4 (熙)
これ以外は独自の実装が多く、使用には注意が必要です。
Code Page 932 (CP932)
MicrosoftによるShift_JISの実装です。
CP932には重複コードがあるため、Unicodeとは単純に変換できないことがあります。[PRB] SHIFT - JIS と Unicode 間の変換問題
参考
EUC (Extended Unix Code)
Unix向けの文字コードで、文字体系ごとに次のようなコードがあります。
- EUC-JP … 日本語EUC
- EUC-KR … 韓国語EUC
- EUC-CN … 簡体字中国語EUC (中国向け)
- EUC-TW … 繁体字中国語EUC (台湾向け)
EUC-JP
- JIS X 0208:1990 (EUC-JP)
- JIS X 0213:2004 (EUC-JIS-2004 / JIS2004)
- eucJP-ms
- CP51932 (Windows Codepage 51932) iana.org/assignments/charset-reg/CP51932
文字コードの変換
ツールによる変換
- WindowsでUnicode文字を簡単に入力したり、Unicodeの文字コード番号を調べたりする方法:Tech TIPS - @IT 打越浩幸 (2016/06/22)
プログラムによる変換
- Tech TIPS:WindowsのPowerShellで複数のファイルの文字コードを一括変換する - @IT 山田祥寛 (2008/04/18)
ツール
文字コードが不明な文字は、バイナリエディタでデータを確認することで推測できます。
文字コード表 (Character Map)
Windows付属のツールで、インストールされているフォントの一覧から、文字コードを確認できます。このツールの実体は、%WINDIR%\System32\charmap.exeにあります。
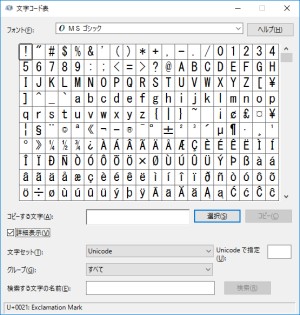
たとえばShift_JISの「あ」のコードを調べるには、グループを[シフト JIS カテゴリによる入力]とし、カテゴリで[ひらがなとカタカナ]を指定します。そうすると仮名文字だけが表示されるため、そこで「あ」を選択するとウィンドウ下部に「U+3042 (0x82A0): Hiragana Letter A」と表示され、Shift_JISのコードで「0x82A0」であることを確認できます。
参考
- 本当は怖い文字コードの話:連載|gihyo.jp … 技術評論社 はせがわようすけ (~2009/12/14)
- 文字コードの基本:ITpro 末安泰三 (2007/03/12)
- 日本語と文字コード - The Web KANZAKI
- もしも文字化けで困ったら | IBM developerWorks 中島由貴ほか (2011/03/17)